
В DeepMind создали алгоритм IMPALA, способный обучаться в сложных средах
14.02.2018В британской Deepmind поставили перед собой очередную сложную задачу - ускорить обучение искусственного интеллекта, что критически необходимо для перехода от обучения в простой среде к обучению функционированию в сложной среде или различных средах.
Разработанный алгоритм DeepRL (от англ. Deep Reinforcement Learning - глубокое обучение с подкреплением) показывал заметные успехи при решении ряда задач, начиная от управления роботами до прохождения игр Go и Atari. Но под каждую отдельную задачу нейросеть приходилось обучать, что называется, с нуля. Обученный алгоритм мог затем хорошо справляться с решением задачи для которой он обучался, но для любой другой задачи процесс приходилось начинать с нуля.
В DeepMind создали обучающую среду DMLab-30, представляющую собой набор задач в визуально похожей среде. Чтобы обучить сеть решать одновременно самые разные задачи, требуется высопроизводительное решение, которое было бы способно использовать всю собранную информацию и полученные навыки. В Deepmind разработали масштабируемое решение для распределенного обучения под названием IMPALA (от англ. Importances Weighted Actor-Learner Architectures - Архитектура основанная на обучении действующего персонажа со взвешиванием важности), которое использует новый алгоритм коррекции политик без необходимости остановок для синхронизации под названием V-trace.
DMLab-30 - это оупенсорсная среда, которую любой разработчик ИИ, основанных на глубоком обучении с подкреплением, может использовать для тестирования систем на наборе интересных задач, в том числе, в многозадачном варианте. В DMLab-30 включены самые разные задачи, отличающиеся по цели, задаче, объемам памяти, навигации. Они представляют самые разные пейзажи и обстановку. В некоторых сценариях присутствуют “боты”, действующие в своих собственных целях. Цели и вознаграждения отличаются в зависимости от уровня, как отличаются языки команд и клавиши, которые отвечают, например, за открывание дверей и т.п.
Более детальное описание среды можно найти здесь:
IMPALA основана на распространенной архитектуре A3C, которая подразумевает, что множество распределенных “действующих лиц”, актеров, обучаются выполнению функций действующих агентов. Обычно такие агенты используют единые настройки политики.
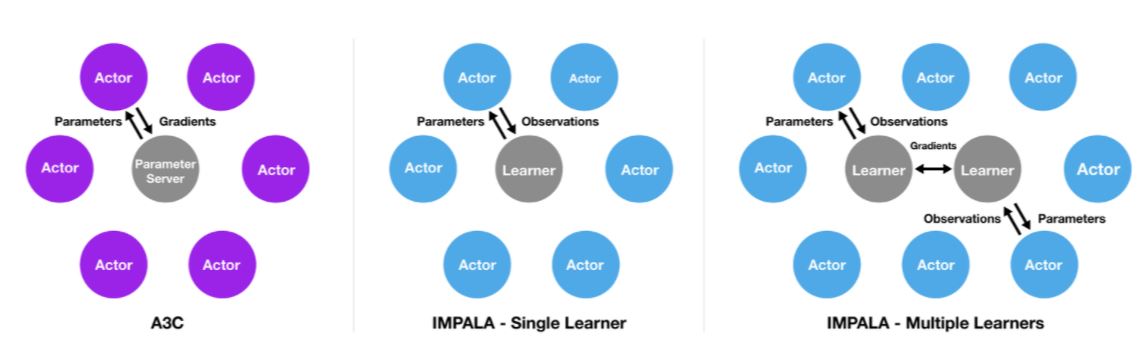
Периодически актеры останавливаются и обмениваются вычисленными градиентами для синхронизации настроек политики. Актеры в IMPALA не занимаются вычислением градиентов. Вместо этого они накапливают опыт, который передается “главному обучающемуся”, который и рассчитывает градиенты, формируя модель, в которой действуют независимые актеры и обучающиеся.
Современные вычислительные средства позволяют развернуть IMPALA на одной “обучающейся машине” или на множестве машин, которые будут обмениваться синхронизирующими их апдейтами. Разделение обучения и действия обеспечивает рост производительности всей системы, поскольку актерам более не нужно ожидать каждого отдельного шага в процессе обучения, как это требовалось в архитектурах типа A2C.
Разделение процесса действий и обучения приводит к тому, что политика каждого актера отстает от политики, формируемой главным обучающимся. Чтобы справиться с этой проблемой, в DeepMind используют алгоритм V-trace, который обеспечивает компенсацию траекторий актеров. .
IMPALA ускорила обучение алгоритма на 1-2 порядка по сравнению с другими подходами, что позволяет решать задачи обучения действиям в сложной внешней среде. Обучаемость системы почти линейно растет с повышением задействованных вычислительных ресурсов, что позволяет наращивать число одновременно действующих актеров и обучающихся при объединении в сеть сотен или тысяч вычислительных машин.
В тестах в DeepMind было достигнуто 10-кратное превышение производительности IMPALA по-сравнению с распределенной реализацией A3C. Кроме того, IMPALA позволила перейти от обучения в одной среде, к обучению в мультисредах. .
+ +









